O modelo foi testado contra a realidade
Antes de prever 2026, reproduzimos o forecast completo das três últimas Copas treinando apenas com dados anteriores a cada uma — e medimos contra os 192 resultados reais. Esta página apresenta as métricas, a comparação entre o modelo estatístico (Poisson), a rede neural e o ensemble, e o resultado final projetado.
01Resultado final projetado — Copa 2026
 Argentina
Argentina1 × 1 · decisão nos pênaltis
 Espanha
EspanhaProbabilidade de título — ensemble validado
Espanha Inglaterra Argentina
Inglaterra Argentina França
França Portugal
Portugal Brasil
BrasilMédia dos modelos Poisson e rede neural (60.000 simulações cada), conforme protocolo validado no backtest.
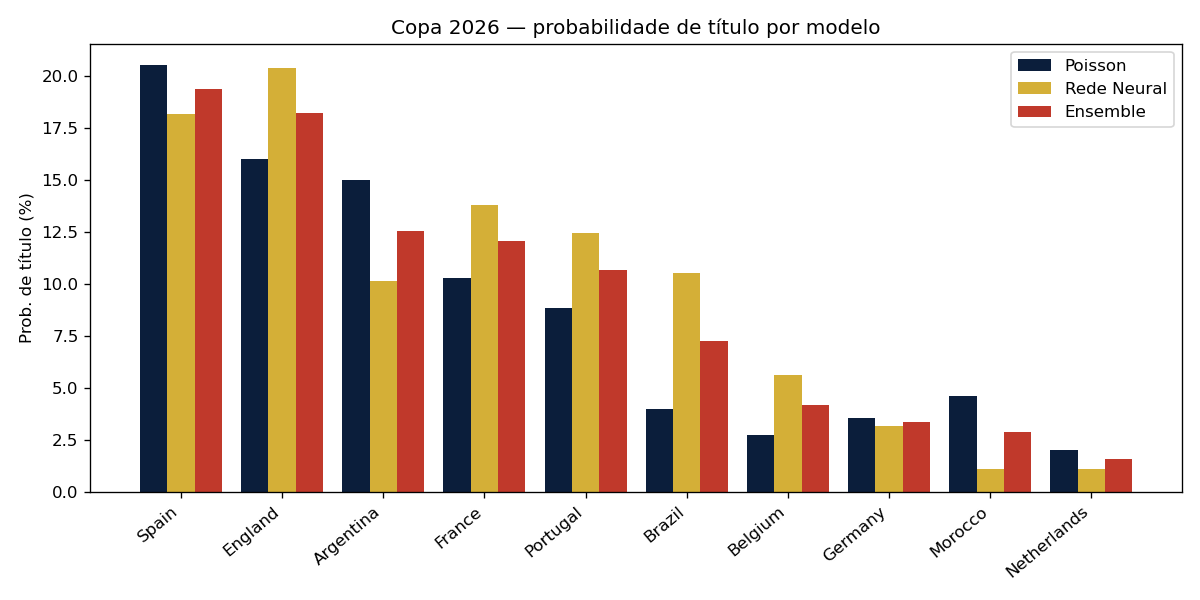
Os três modelos lado a lado
| Seleção | Poisson | Rede Neural | Ensemble |
|---|---|---|---|
| Espanha | 20,6% | 18,2% | 19,4% |
| Inglaterra | 16,1% | 20,4% | 18,2% |
| Argentina | 15,0% | 10,2% | 12,6% |
| França | 10,3% | 13,8% | 12,1% |
| Portugal | 8,9% | 12,5% | 10,7% |
| Brasil | 4,0% | 10,5% | 7,3% |
| Bélgica | 2,7% | 5,7% | 4,2% |
| Alemanha | 3,6% | 3,2% | 3,4% |
A rede neural valoriza Brasil e Inglaterra; o Poisson, Argentina e Marrocos. O ensemble equilibra as duas leituras.
02Backtest: reproduzimos 2014, 2018 e 2022 sem olhar o futuro
Para cada Copa, o modelo foi treinado somente com jogos anteriores ao torneio (corte temporal estrito, elencos e rankings da época reconstruídos de fontes datadas) e o torneio inteiro foi simulado 50.000 vezes. As previsões foram então confrontadas com o que de fato aconteceu.
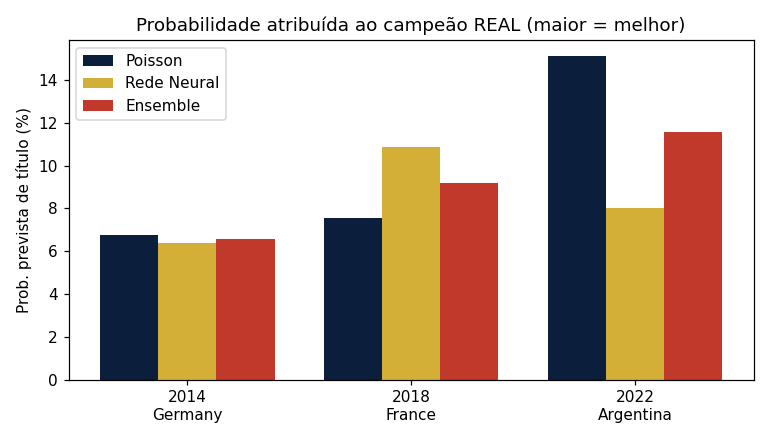
Onde o campeão real ficou no ranking previsto
| Copa | Campeão real | Poisson | Rede Neural | Ensemble |
|---|---|---|---|---|
| 2014 | 🇩🇪 Alemanha | 4º · 6,8% | 4º · 6,4% | 4º · 6,6% |
| 2018 | 🇫🇷 França | 6º · 7,5% | 5º · 10,9% | 5º · 9,2% |
| 2022 | 🇦🇷 Argentina | 2º · 15,1% | 5º · 8,0% | 2º · 11,6% |
Em todas as Copas o campeão real estava entre os 6 favoritos do modelo; em 2022, o ensemble o colocou em 2º. Acertar campeão de Copa é estruturalmente difícil — até o favorito máximo raramente passa de ~20%.
03Jogo a jogo: 192 partidas reais, 4 métricas
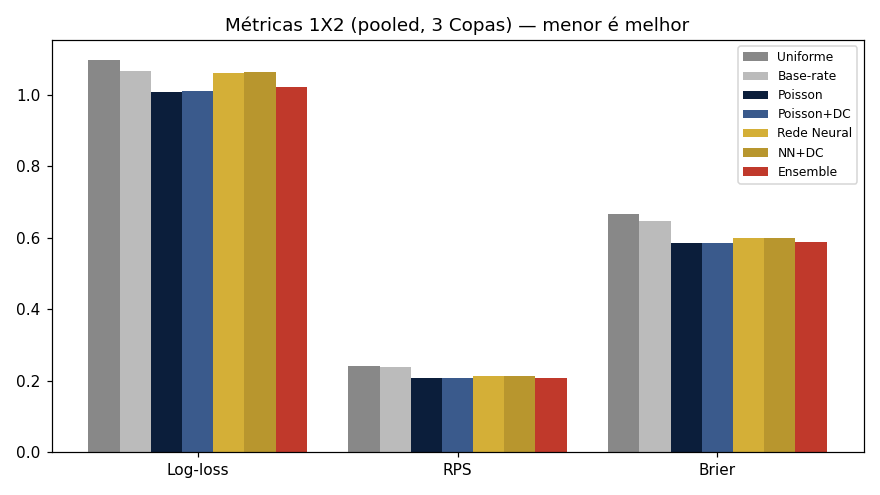
| Método | Log-loss ↓ | Brier ↓ | RPS ↓ | Acurácia ↑ |
|---|---|---|---|---|
| Chute uniforme (⅓·⅓·⅓) | 1,0986 | 0,6667 | 0,2422 | 42,7% |
| Frequência histórica de Copas | 1,0657 | 0,6461 | 0,2387 | 42,7% |
| Poisson melhor calibração | 1,0075 | 0,5844 | 0,2073 | 56,2% |
| Rede Neural melhor acurácia | 1,0611 | 0,5985 | 0,2134 | 58,3% |
| Ensemble (Poisson + NN) recomendado | 1,0231 | 0,5882 | 0,2087 | 57,3% |
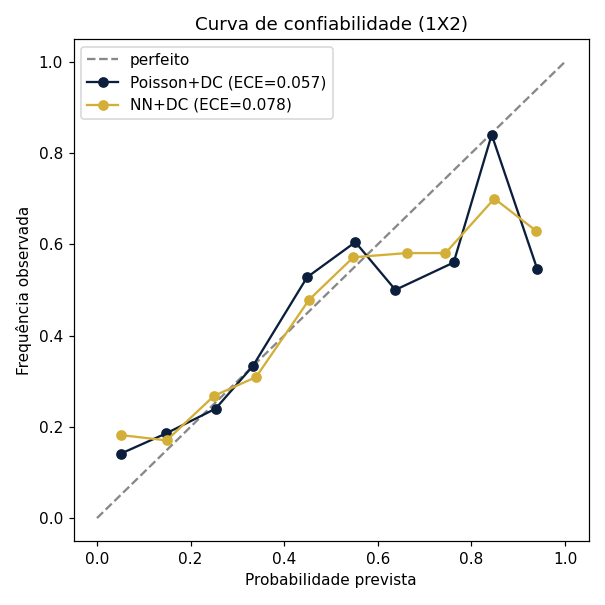
Log-loss/Brier/RPS medem a qualidade das probabilidades; acurácia mede acerto seco do resultado 1X2. O Poisson dá as probabilidades mais honestas; a rede neural acerta mais vencedores; o ensemble une os dois mundos. Calibração (ECE): Poisson+DC 0,057 · Ensemble 0,062 · NN+DC 0,078.
Por Copa (log-loss · acurácia)
| Copa | n | Poisson | Rede Neural |
|---|---|---|---|
| 2014 | 64 | 0,976 · 59,4% | 1,006 · 60,9% |
| 2018 | 64 | 0,980 · 56,2% | 1,014 · 59,4% |
| 2022 | 64 | 1,067 · 53,1% | 1,153 · 57,8% |
2022 (Catar) foi a Copa mais imprevisível das três para todos os modelos — coerente com as zebras históricas daquela edição (Arábia Saudita × Argentina, Marrocos semifinalista).
04O que foi testado e rejeitado — transparência metodológica
| Experimento | Motivação | Veredito |
|---|---|---|
| Correção Dixon-Coles (empates) | Poisson independente subestima empates | ADOTADO melhora na validação interna |
| Deep ensemble de seeds (NN) | Reduzir variância de treino | ADOTADO K=3, ganho marginal |
| Busca de hiperparâmetros | Rede menor e mais regularizada | ADOTADO hidden=8, dropout=0,3 |
| Temperatura de calibração | Corrigir overconfidence | REJEITADO T≈1,00 — NN já calibrada internamente |
| Elo como feature da rede | Sinal de qualidade por partida | REJEITADO redundante com embeddings |
| Modelo Elo→gols no ensemble | Diversidade de modelo | REJEITADO piora todas as combinações |
| Ranking FIFA mensal externo | Feature de qualidade | DESCARTADO defasado e subsumido pelo Elo |
Toda decisão foi tomada em validação temporal interna (últimos 15% do treino), nunca nos jogos de Copa usados como teste — protocolo anti-overfitting pré-comprometido. Lição central dos experimentos: derivados do próprio histórico de placares (Elo, rankings) não acrescentam sinal ao Poisson; o próximo salto exige dados externos (odds de mercado, xG, dados por jogador).
05Como o modelo funciona
Pipeline
1. Regressão de Poisson (ataque/defesa/mando por seleção) sobre ~18.800 jogos desde 2007, com peso por recência e importância do torneio.
2. Rede neural (PyTorch): embeddings de ataque/defesa + MLP de forma recente, perda Poisson, ensemble de 3 seeds.
3. Ajuste por força de elenco 2026 (valor de mercado, ranking FIFA, forma, desfalques).
4. Monte Carlo: 60–200 mil torneios completos (grupos com critérios FIFA, repescagem de terceiros, mata-mata com pênaltis).
5. Ensemble: média das probabilidades dos dois modelos.
Limites honestos
· Futebol tem variância irredutível: o melhor favorito do mundo fica em ~20% de título.
· 3 Copas = amostra pequena no nível torneio; o peso da validação está nos 192 jogos.
· O modelo não vê lesões de última hora, clima, arbitragem ou dinâmica de vestiário.
· Probabilidades calibradas significam: entre 10 eventos previstos com 30%, ~3 devem acontecer — não que o favorito sempre vence.